Decoupling Skill Learning from Robotic Control for Generalizable Object Manipulation
Kai Lu1, Bo Yang2, Bing Wang1, Andrew Markham1
1 K. Lu, B. Wang, and A. Markham are with the Department
of Computer Science, University of Oxford, Oxford, UK. {kai.lu, bing.wang, andrew.markham}@cs.ox.ac.uk
2 B. Yang is with vLAR Group, Department of Computing, Hong Kong Polytechnic University, HKSAR. bo.yang@polyu.edu.hk
paper link
Summary Video (ICRA 2023)
Abstract
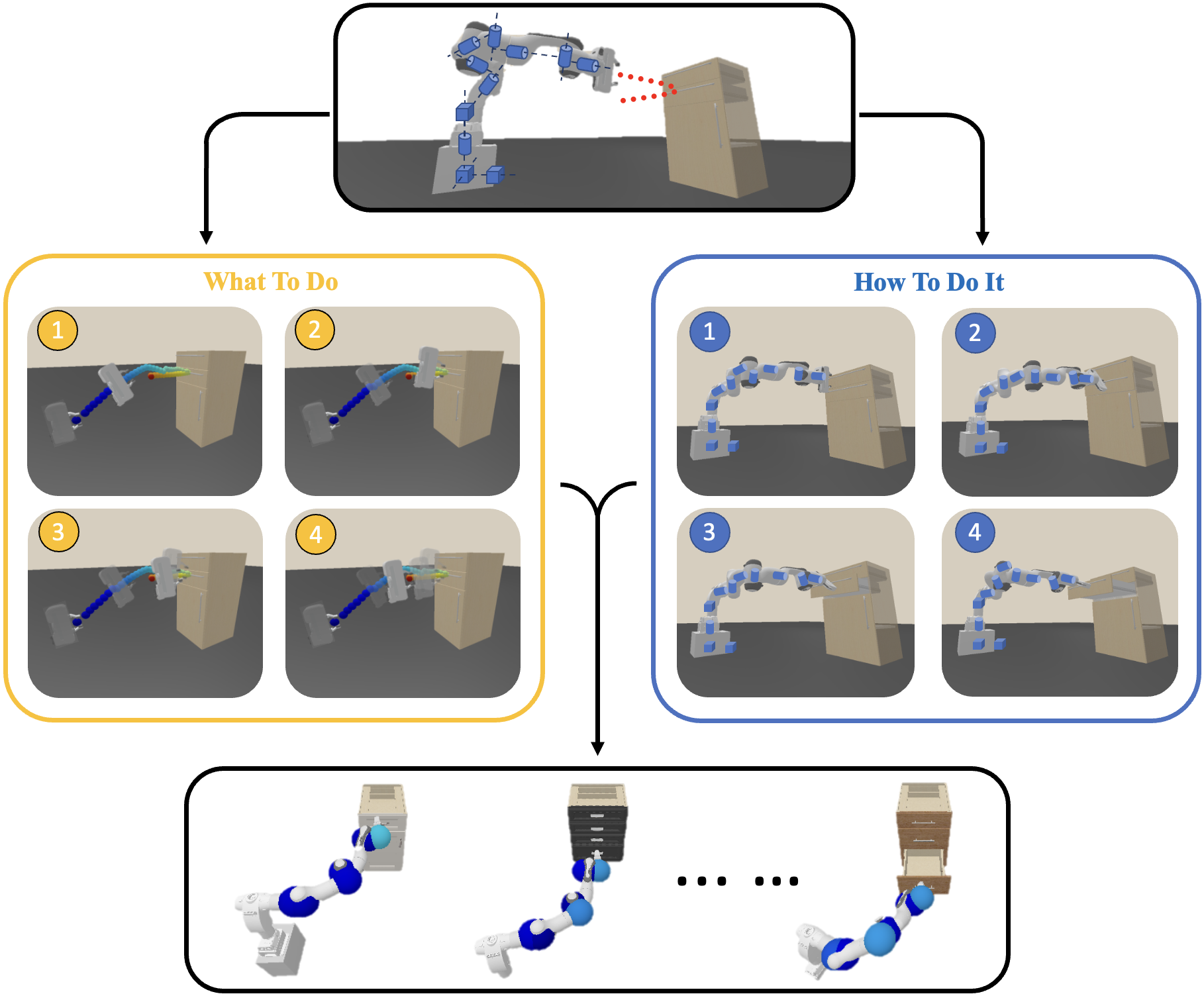
Robotic reinforcement learning (RL) and imitation learning (IL) have recently shown potential for tackling a range of tasks e.g., opening a drawer or a cupboard, but they generalize poorly to unseen objects. In this paper, we separate the task of learning 'what to do' from 'how to do it' i.e., whole-body control (WBC). We pose the RL problem as one of determining the skill dynamics for a disembodied virtual manipulator interacting with articulated objects (left panel). The QP-based WBC is optimized with singularity and kinematic constraints to execute the high-dimensional joint motion to reach the goals in the workspace (right panel). Experiments on manipulating complex articulated objects show that our approach is more generalizable to unseen objects with large intra-class variations. It also generates more compliant robotic motion, and outperforms the pure RL and IL baselines in task success rates (bottom panel). quick view of example results (click)
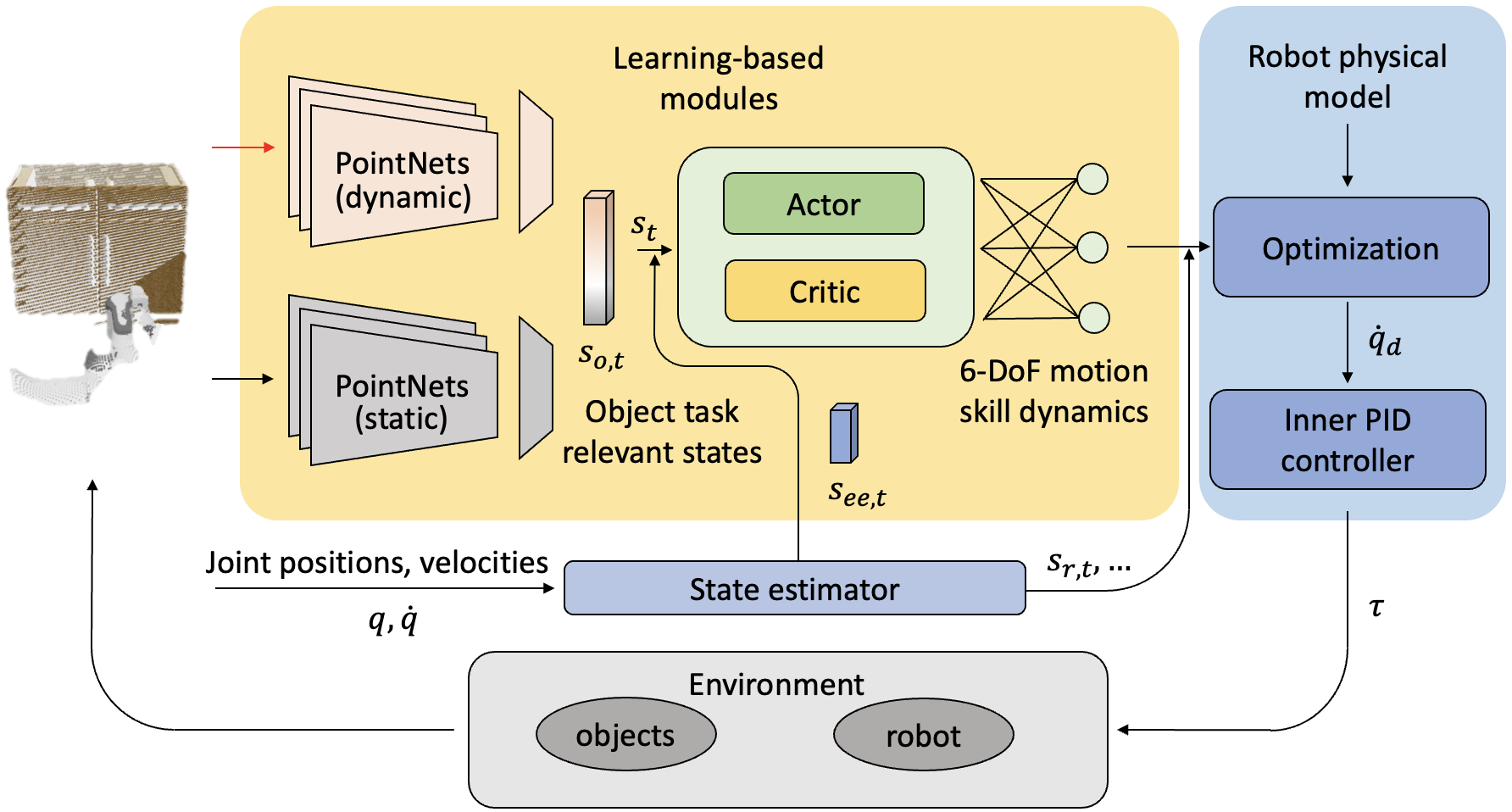
Pipeline
As shown in the yellow block, we use two simple PointNet ensembles to separately perceive static (e.g., size of an object) and dynamic (e.g., current position of a handle) states. These are inputs to a SAC RL framework to learn how to control the disembodied end-effector, realizing a 6-DoF motion skill. Through knowledge of the robot's physical model, QP is used to optimize control of the joint dynamics of the whole-body robot.
Training process
During training process (left), the disembodied manipulator interactes with various cabinets. Test on unseen cabinets (right): by interacting with more cabinets, the RL model shows a better understanding of the skill dynamics, resulting in smoother and more reasonable motions.
Whole-body control
At every time step, the ego-centric point cloud observation is obtained from the three RGB-D cameras mounted on the robot.
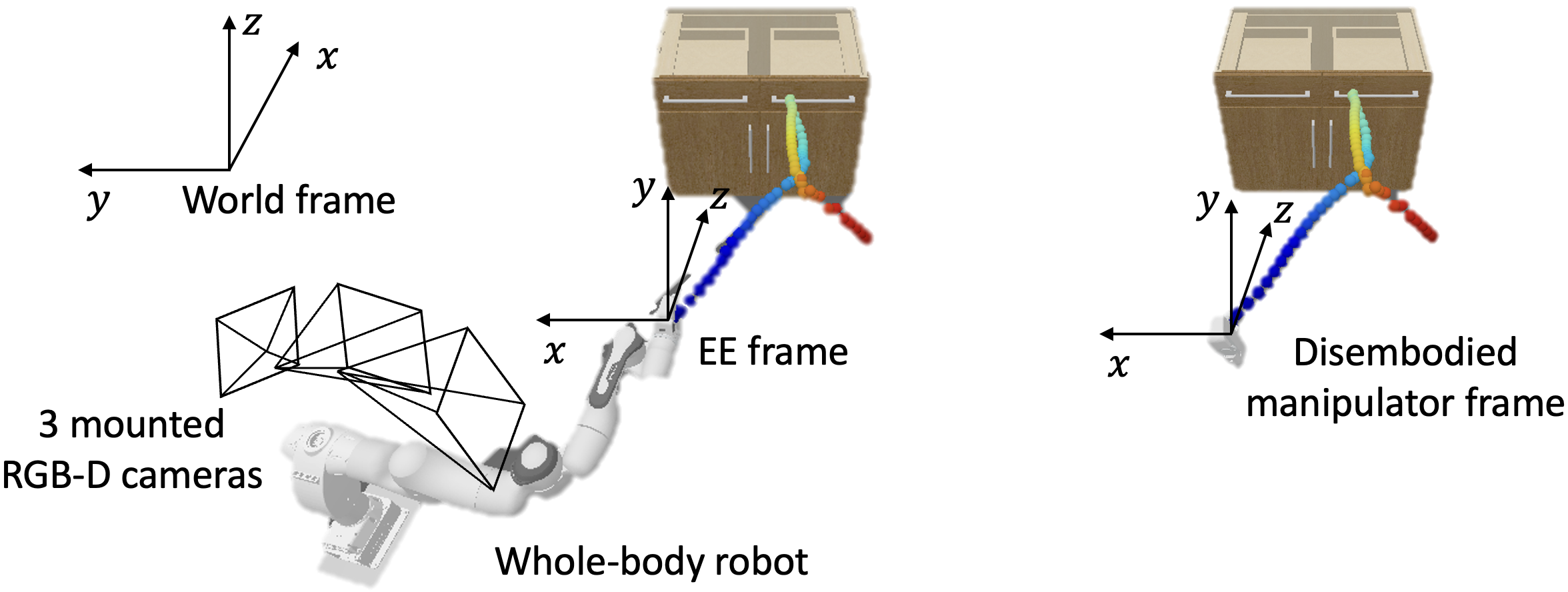
During the manipulation process, we optimize the joint-space actions of the robot to approximate its end-effector (EE) motions to the disembodied manipulator's trajectory. We use a QP-based WBC with robotic singularity and kinematic contraints to solve the high-dimensional joint actions.
Example Results
Generalizability to different unseen objects
Experiments show that our approach can learn generalizable skills over different cabinets of the training sets and unseen test sets. We achieve an average success rate of 74% on training cabinets and a 51% on test cabinets in the drawer opening task, significantly out-performing existing techniques (e.g., the baseline methods in ManiSkill-Learn1 obtain a best performance of 37% on training cabinets and a 12% on test cabinets).
Motion Compliance
We also compare the robotic motions produced by our method and pure RL and IL (left: BC in 0:00~0:12, BCQ in 0:13~0:25), showing that robot singularities are avoided in most cases by our method (right: ours). Note that BC and BCQ exhibits far high joint velocities, while our approach generates more compliant, smoother, and controllable robot motions.
Contact
Have any questions, please feel free to contact Kai Lu
March, 2023
Copyright © Kai Lu